|
Jinlong Li (李金龙)
Pushing a long-termist, strike the tough yet right things correctly. |




Biography
I will join in ETH Zurich as a visiting student at the Computer Vision and Geometry Group (CVG), under the supervision of Prof. Marc Pollefeys. I am now a PhD student at the Multimedia and Human Understanding Group (MHUG), under the supervision of Prof. Nicu Sebe. Previously, I worked at MeiTuan as a computer vision scientist, working closely with Dr. Lin Ma and Dr. Zequn Jie, focusing on 2D/3D/4D Label-Efficient Detection and Segmentation. Before that, I obtained my dual B.Sc (main Applied Physics) and M.Sc (Computer Science) degree in Shenzhen University.
Research Interest
I work in the field of Computer Vision and Deep Learning. Recently, I focus on research topics to build machines that can see, reason about, and interact with the geometric and physical world through end2end unify paradigm, while exploring various domains:- Multi-Modal Perception, Reasoning and Planning Learning
- Spatial Foundation Models
- Generative Models
- Label-Efficient Learning on both 2D, 3D and 4D
News
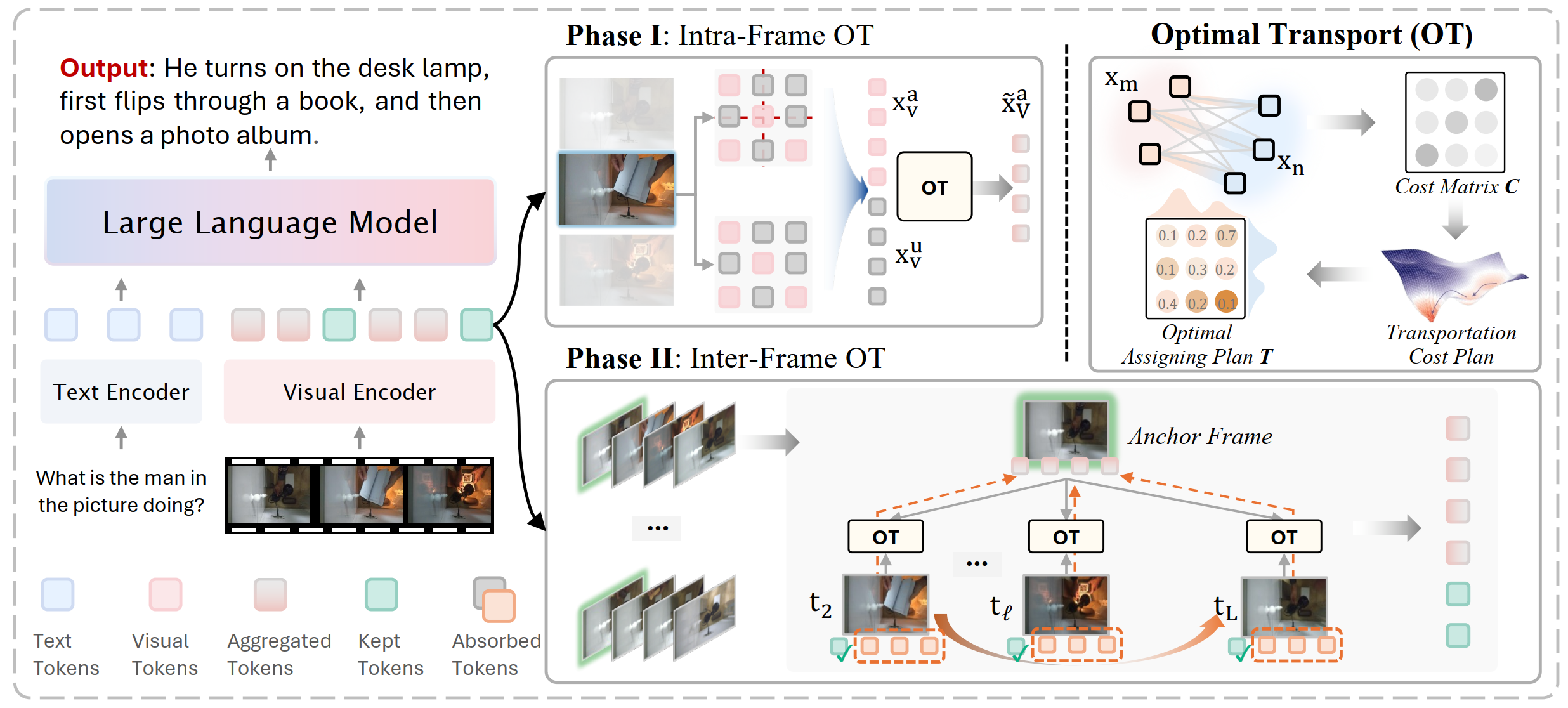
- 2026 Feb.: Our work AOT, got accepted by CVPR2026! Congrats to all co-authors!
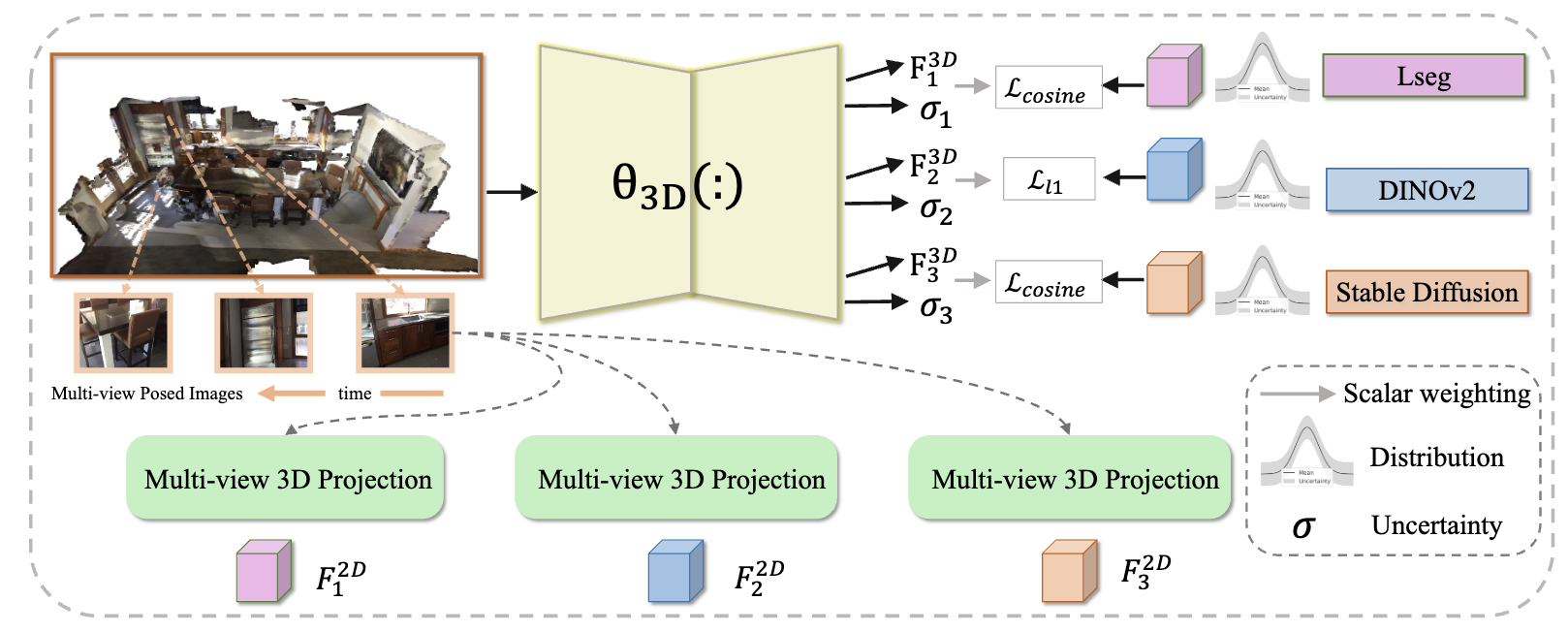
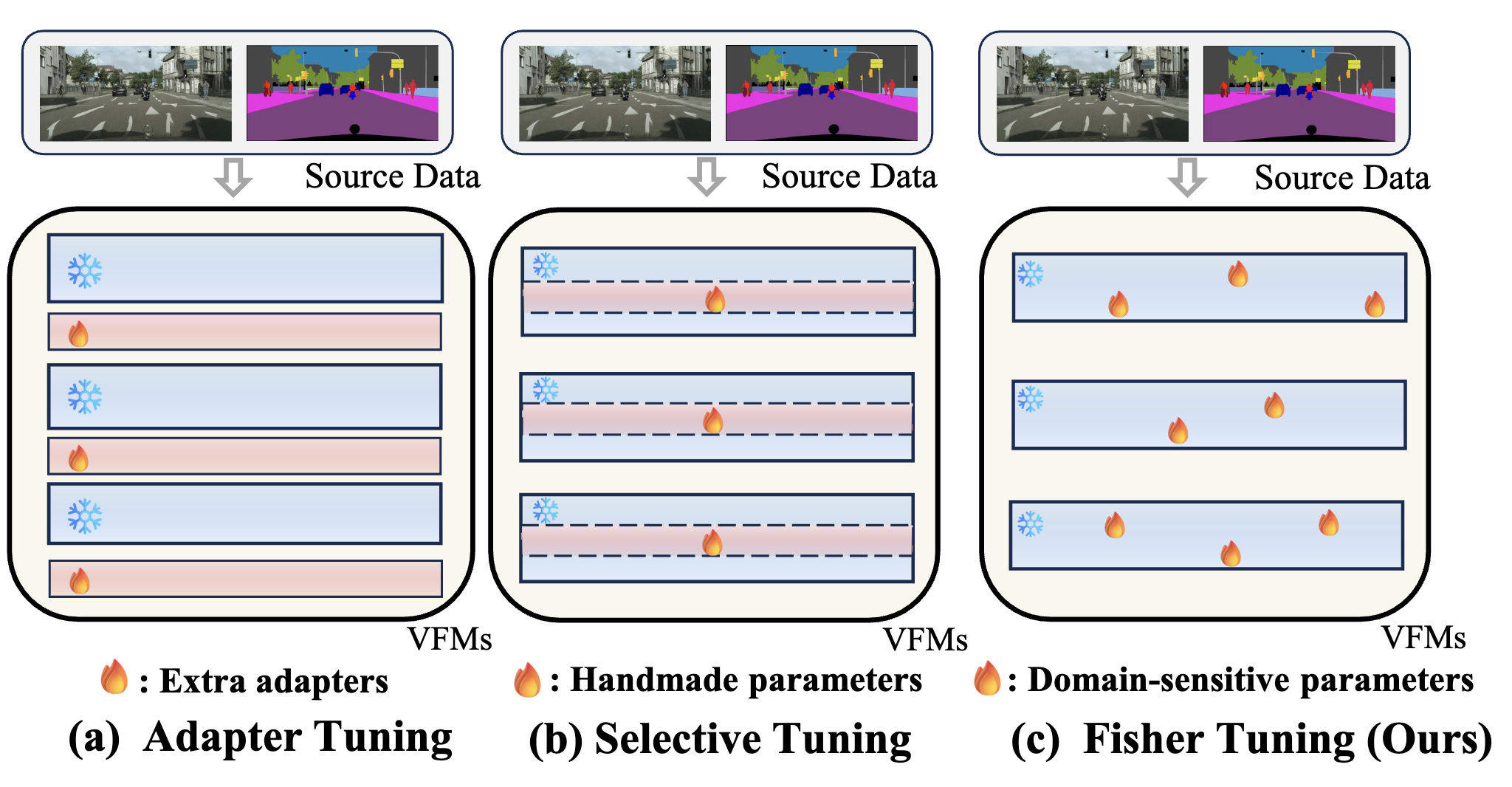
- 2025 Feb.: Our works CUA-O3D and FisherTune, got accepted by CVPR2025! Congrats to all co-authors!
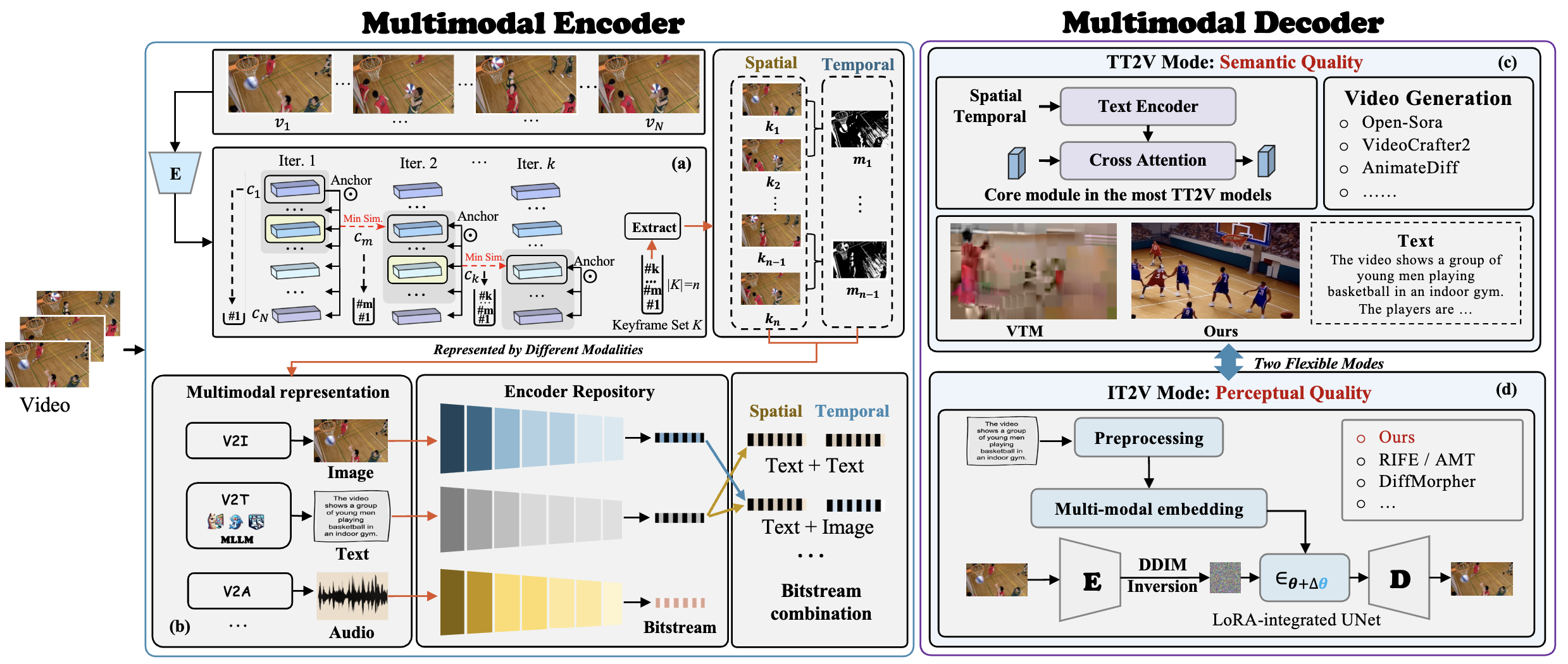
- 2024 Sept.: Our work LESS got accepted by NeurIPS 2024!
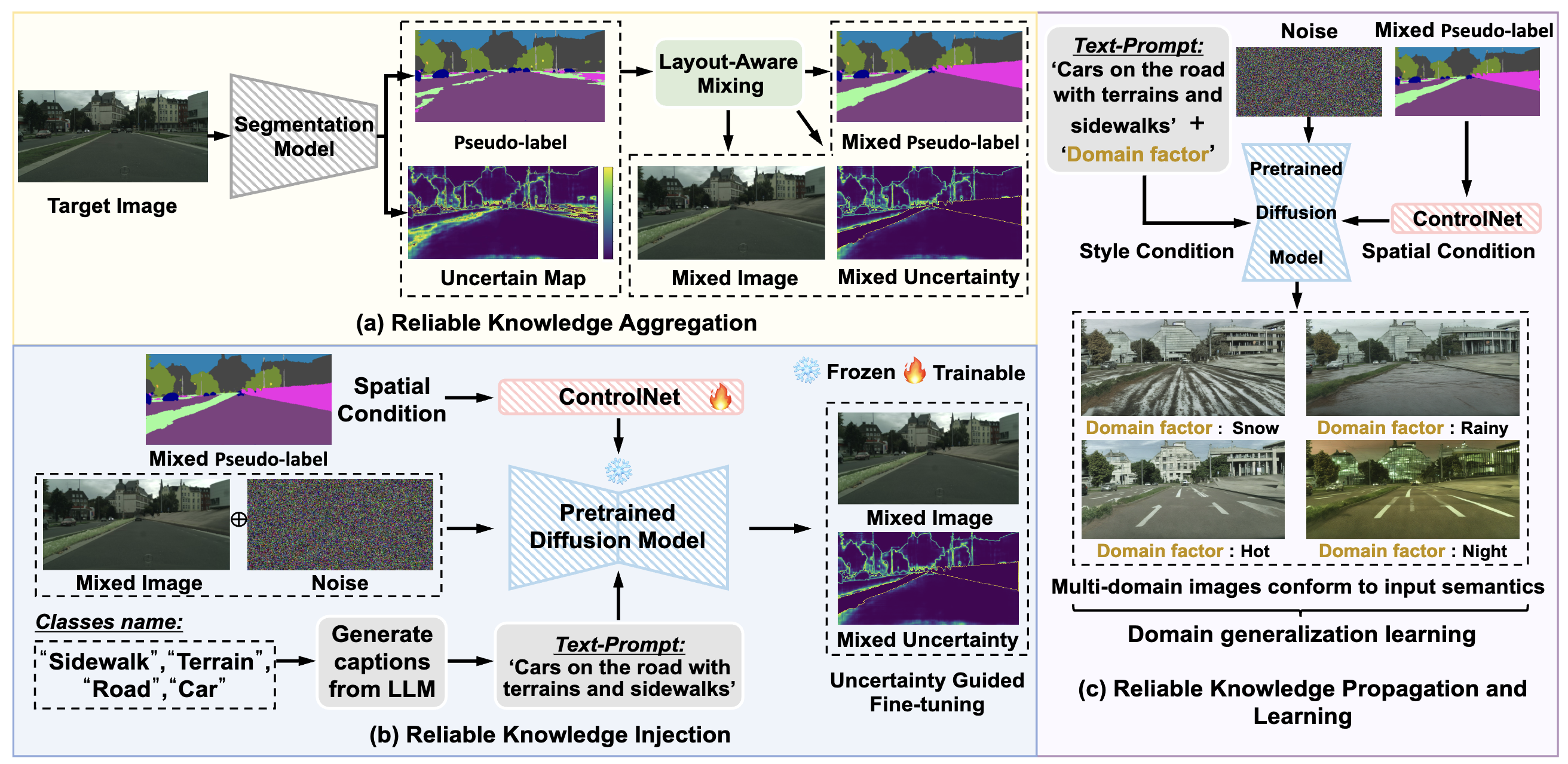
- 2024 July.: Our work RKP got accepted by ACM MM 2024!
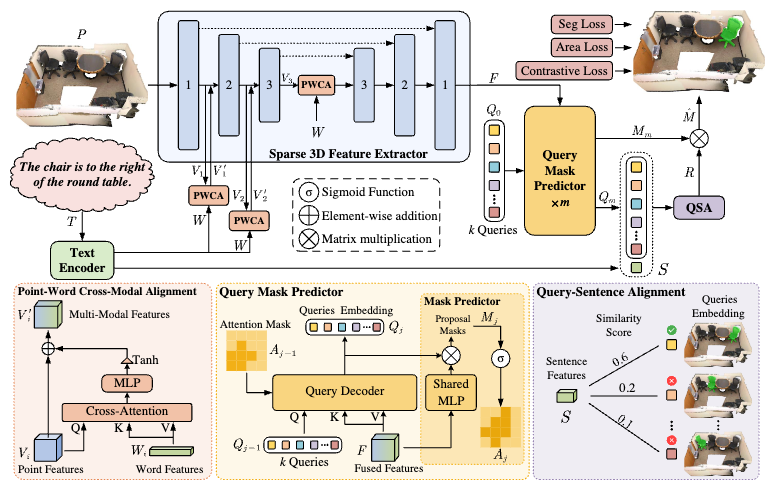
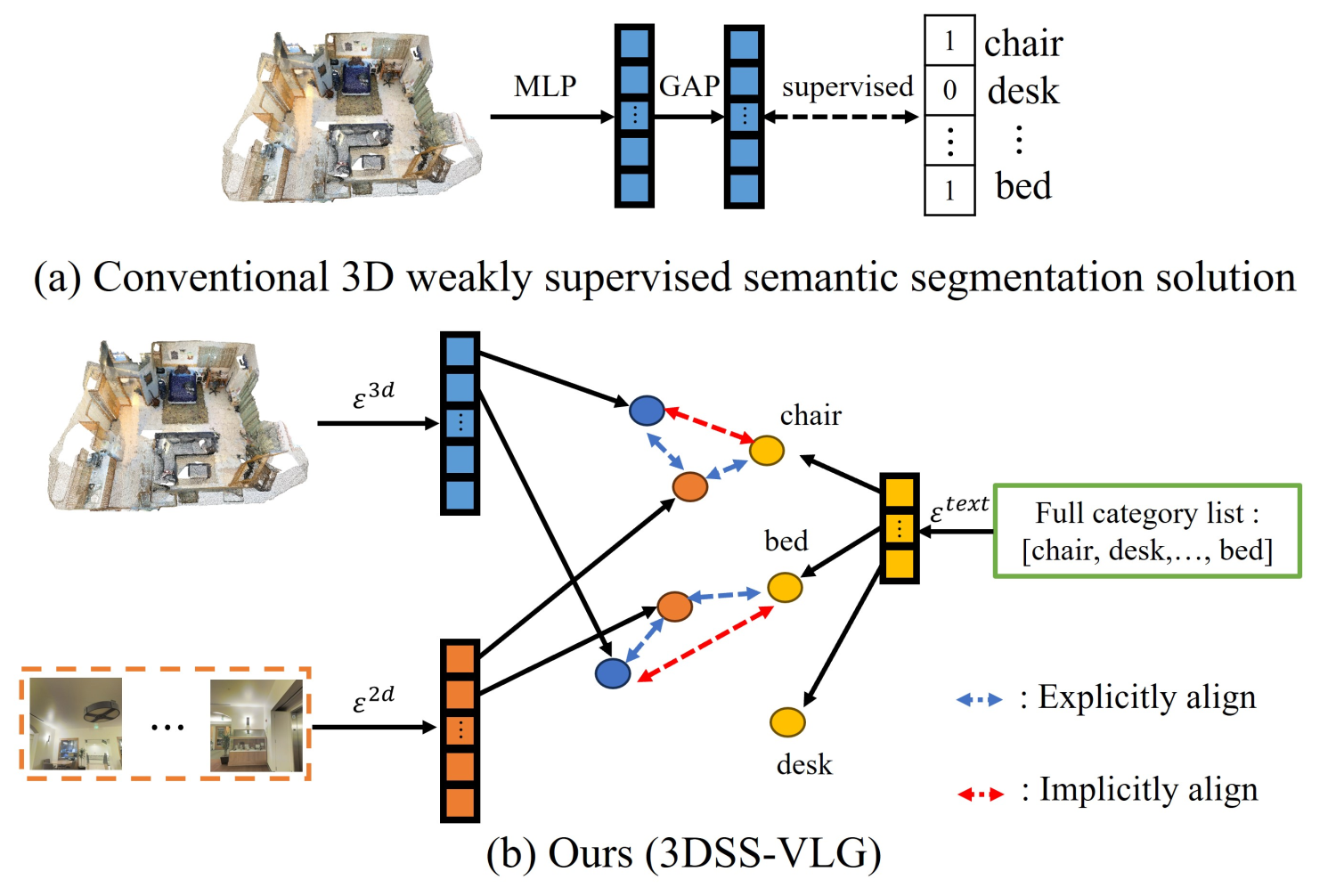
- 2024 July.: Our work 3DSS-VLG got accepted by ECCV 2024!
- 2023 Feb.: One paper got accepted by Neurocomputing 2023!
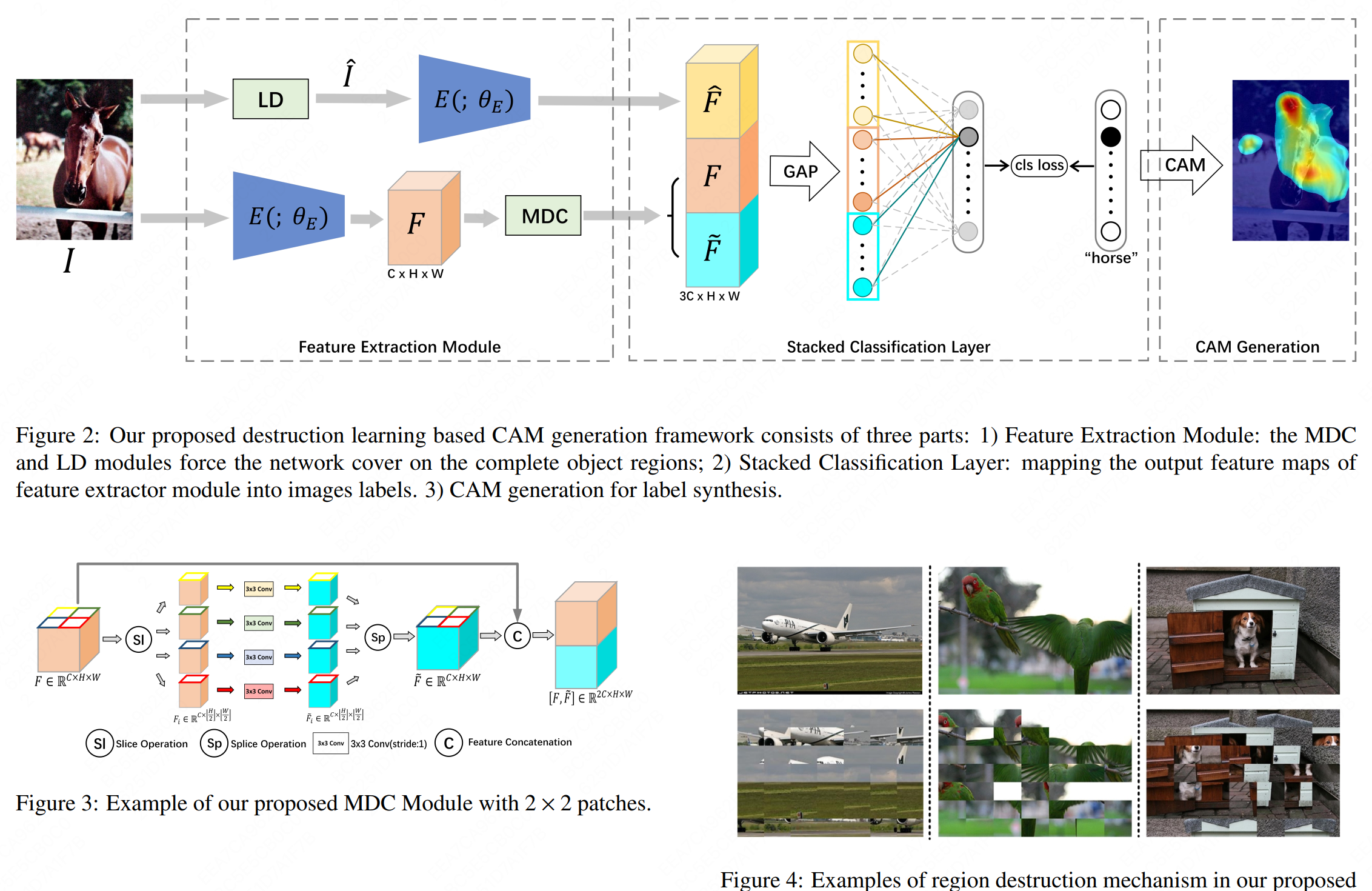
- 2022 Sept.: Our work ESOL got accepted by NeurIPS 2022!
- 2022 Feb.: Our work PPL got accepted by TMM 2022!